

PTT爬蟲系列文之MARVEL篇,將鬼怪討論串的內容,將討論度高的文章結錄存至本機電腦記事本中。
引用python套件
- BeautifulSoup
用於解析html DOMpip3 install beautifulsoup4 - requests
用於對網址發出http requestspip3 install requests
程式碼
- 架構
- 程式碼解析
- Demo
架構
|
1 2 3 4 5 6 7 8 9 10 11 12 |
st=>start: 程式進入點 op1=>operation: 讀取PTT Marvel首頁 op2=>operation: 設定讀取頁數 op3=>operation: 解析HTML DOM op4=>operation: 儲存檔案 op5=>operation: 前往下一頁URL cond=>condition: 是否最後一頁? e=>end: 程式結束 st->op1->op2->op3->op4->cond cond(yes)->e cond(no)->op5->op3 |
程式碼解析
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
from bs4 import BeautifulSoup import requests def main(): # 頁面URL URL_now = "https://www.ptt.cc/bbs/marvel/index.html" # 跑的次數 targetLoop = 100 countLoop = 1 while countLoop<=targetLoop: print("Page: " + str(countLoop) + "/ " + str(targetLoop)) returnURL = parsePage(URL_now) URL_now = returnURL countLoop+=1 """ 找爆文 存入list """ def parsePage(pageURL): res = requests.get(pageURL) soup = BeautifulSoup(res.text, 'html.parser') articleList = findAllTitle(soup) href_list = list() for div in articleList: try: if (((div.find('div', class_='title').text.split('['))[1].split(']'))[0]) != "創作" and (((div.find('div', class_='title').text.split('['))[1].split(']'))[0]) != "公告": if ('爆' == div.find('div', class_='nrec').text): content_list = list() content_list.append(div.find('div', class_='title').text.split('\n')[1]) content_list.append(div.find('div', class_='title').a.get('href')) href_list.append(content_list) except: print("Can't find '[' in title.") try: if (((div.find('div', class_='title').text.split('['))[1].split(']'))[0]) != "創作" and (((div.find('div', class_='title').text.split('['))[1].split(']'))[0]) != "公告": if ('爆' == div.find('div', class_='nrec').text): content_list = list() content_list.append(div.find('div', class_='title').text.split('\n')[1]) content_list.append(div.find('div', class_='title').a.get('href')) href_list.append(content_list) except: print("Can't find '[' in title.") for item in href_list: loadArticle(item) # 前往下一頁 nextURL = findNextPageURL(soup) URL_now = "https://www.ptt.cc" + nextURL return URL_now """ 下一頁URL """ def findNextPageURL(HTMLdata): return (HTMLdata.find('div', id='action-bar-container').find_all('a'))[3].get('href') """ 取當前頁面所有文章列 """ def findAllTitle(HTMLdata): # data.find_all('div', class_='title') rows = HTMLdata.find_all('div', class_='r-ent') return rows """ 讀取爆文內容 存入text file """ def loadArticle(data): title = fixFilePath(data[0]) URL = "https://www.ptt.cc" + data[1] res = requests.get(URL) soup = BeautifulSoup(res.text, 'html.parser') content = soup.find('div', id='main-content').text.split('※ 發信站')[0] # save file fp = open("./marvel/" + title + ".txt", "w", encoding='utf-8') fp.write(content) fp.close() """ Fix the illegal file path charactors """ def fixFilePath(oriPath): title = oriPath.replace('/', ' ') title = title.replace('\\', ' ') title = title.replace('"', ' ') title = title.replace('*', ' ') title = title.replace('?', ' ') title = title.replace(':', ' ') title = title.replace(';', ' ') title = title.replace('|', ' ') title = title.replace(',', ' ') title = title.replace('<', ' ') title = title.replace('>', ' ') return title if __name__ == "__main__": main() |
Function解析
– def parsePage(pageURL)
|
1 2 3 |
讀取文章列表HTML DOM,取得人氣為 "爆" 或是大於 85 推以上的文章。 將文章標題及文章URL存入文章list。 呼叫loadArticle,分別處理list中各文章內容。 |
– def findNextPageURL(HTMLdata)
|
1 |
此function將回傳下一頁的URL。 |
– def findAllTitle(HTMLdata)
|
1 |
此function將回傳當前文章列表所有文章標題,唯一list。 |
– def loadArticle(data)
|
1 |
parse文章內容,儲存於txt檔案。 |
– def fixFilePath(oriPath)
|
1 |
處理txt檔案名稱,針對windows不合法的檔案名稱字元進行replace。 |
Demo
資料夾內容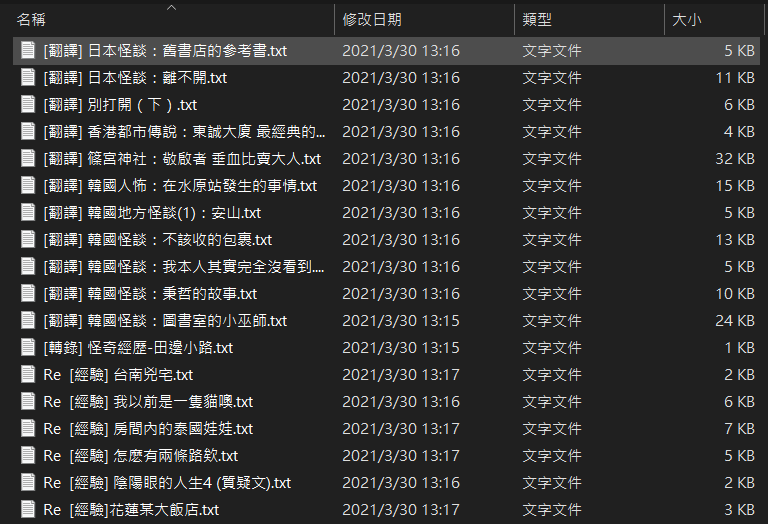
txt內容
留言